LLaVa
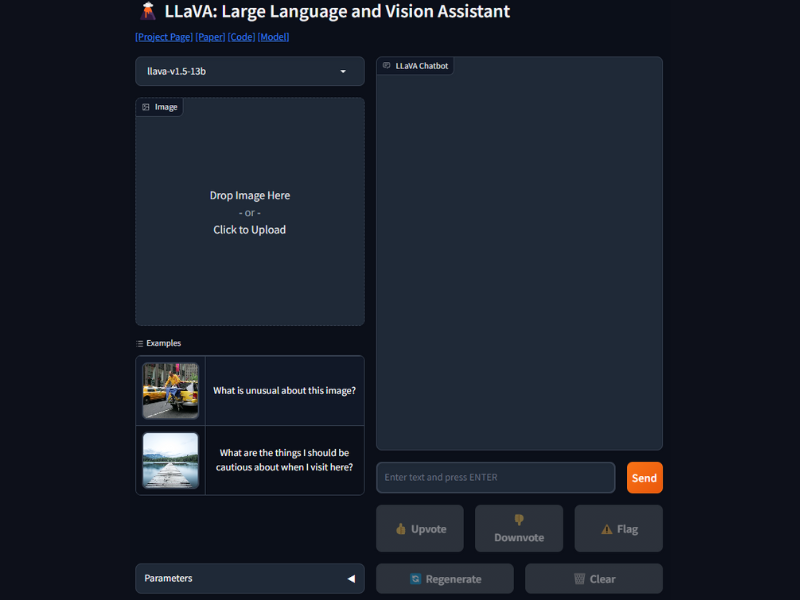
LLaVA (Large Language and Vision Assistant) represents a groundbreaking advancement in multimodal AI technology. This innovative tool seamlessly integrates a vision encoder with a powerful large language model (LLM) named Vicuna. Trained end-to-end, LLaVA excels in general-purpose visual and language understanding. One of its remarkable achievements is its chat capabilities, which mirror the performance of multimodal GPT-4. Additionally, LLaVA sets a new benchmark for accuracy in Science QA tasks, showcasing its versatility and efficiency.
A distinctive feature of LLaVA is its unique ability to generate multimodal language-image instruction-following data using language-only GPT-4, highlighting its adaptability and sophistication in handling complex tasks. Being open-source, LLaVA offers accessibility to its data, models, and code, encouraging collaborative efforts and further advancements in the field of multimodal AI. Its fine-tuning for specific applications, particularly in visual chat and science domain reasoning, attests to its high-performance capabilities and relevance in real-world applications.
